
평소 API 반환값을 추론하기 위해 어떤 방식을 사용하시나요?
Schema Validation Layer 를 추가하면 메인 로직을 깔끔하게 관리할 수 있습니다.
(부제: zod 나 superstruct 를 사용해보아요.)
시작
Axios 를 사용하는 유저라면 반환값으로 예상하는 타입을 get 메서드 제너릭의 첫 번째 인자로 넣는 방식을 자주 사용하실 것입니다.
예를 들면 아래와 같을 거예요.
export default async function fetchPosts() {
const { data } = await axios.get<Post>('https://jsonplaceholder.typicode.com/posts');
return data;
}
export type Post = {
userId: number;
id: number;
title: string;
body: string;
};
그러나, 이러한 방식은 문제점이 있습니다. 반환값이 Post 라고 어떻게 확신하나요?
위 예제도 그렇습니다. 사실 해당 API는 Post[] 를 반환하는데 Post 라고 타이핑을 했음에도 타입 에러가 잡히지 않습니다.
이는 전혀 Type-Safe 하지 않습니다!!
Generic 으로 타입을 넣어주는 방식은 Compile Time 에서 에러가 잡히지 않기 때문에 Runtime 에서 예상치 못한 문제가 터질 수 있습니다.
Schema Validation Layer 를 추가하면 이런 문제를 해결할 수 있습니다.
Validation Layer
Validation Layer 의 요지는 두 계층 사이에서 오고가는 데이터를 검증하는 계층을 두자는 것입니다.
앞선 예시의 문제는 원격 저장소와 데이터를 주고 받는 과정에서 데이터를 검증하는 로직이 없다는 점입니다.
물론, 검증 로직을 아래와 같이 추가할 수도 있겠습니다.
// validation
function isPosts(data: unknown): data is Posts {
return Array.isArray(data);
}
export default async function fetchPosts() {
const { data } = await axios.get<Post>('https://jsonplaceholder.typicode.com/posts');
if (!isPosts(data)) {
throw new Error();
}
return data;
}
checkData 는 data 의 Array 여부를 체크함으로써 Validation Layer 의 목표를 일부 달성하긴 합니다.
그러나 생각해보세요.
- 검증 후 predicate 하는 것은 과연 완벽하게 Type-Safe 한가? (실제로, Array.isArray(data) 분기문 만으로
Post[]라고 보장할 수 없습니다. data 가Post임을 보장할 수 없기 때문이죠.) - 모든 조건을 검증하기 위해선 각 조건에 대한 분기 로직은 어느 정도로 작성해야 하는가?
- 모든 조건을 커버하였다고 가정했을 때, 요구 조건이 변경되어서
Post인터페이스가 달라진다면?
위 문제들을 해결하려고 로직들을 일일히 수정한다고 생각해보세요. 생각만해도 갑갑합니다.
이러한 귀찮은 작업들을 Schema 를 두는 것으로 해결할 수 있습니다.
Schema Validation
NPM 엔 Schema Validation 을 위한 패키지가 정말 많이 있습니다. 링크
다양한 도구가 저마다의 장단점을 갖고 있지만, 해당 문서에선 zod 로 예시를 들도록 하겠습니다.
위 예제를 zod 로 Schema Validaition 을 하면 아래와 같이 작성할 수 있습니다.
(Method 는 다음 섹션에서 가볍게 설명할테니, 지금은 흐름만 봐주세요.)
import axios from 'axios';
import { z } from 'zod';
export type Post = z.infer<typeof Post>;
export const Post = z.object({
userId: z.number(),
id: z.number(),
title: z.string(),
body: z.string(),
});
export type Posts = z.infer<typeof Post>;
export const Posts = z.array(Post);
/* Type Inference:
function fetchPosts(): Promise<{
userId: number;
id: number;
title: string;
body: string;
}[]>
*/
export default async function fetchPosts() {
const { data } = await axios.get('https://jsonplaceholder.typicode.com/posts');
return Posts.parse(data);
}
만약 잘못된 Schema 로 parse 를 시도한다면, ZodError 를 throw 합니다.
export default async function fetchPosts() {
const { data } = await axios.get('https://jsonplaceholder.typicode.com/posts');
+ return Post.parse(data);
- // return z.array(Post).parse(data);
}
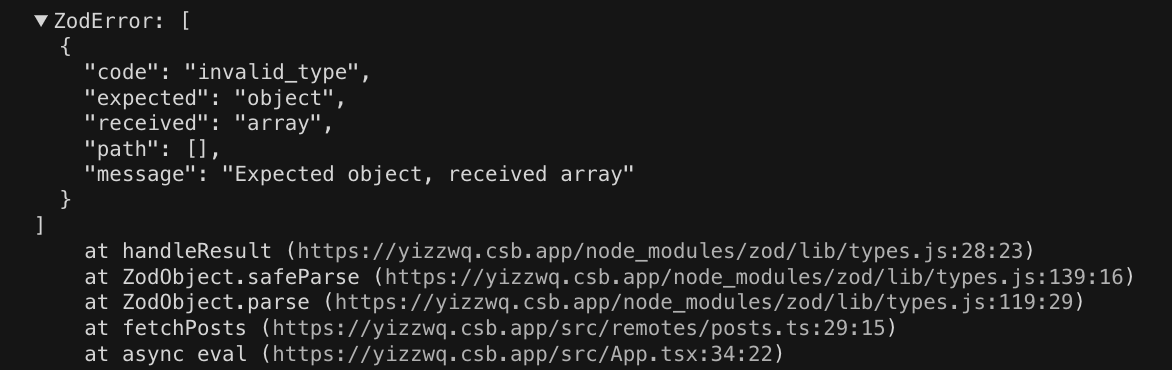
zod 는 schema 단에서 데이터를 다룰 수 있는 매우 많은 method 를 제공해줍니다.
그리고, infer method 를 사용하면 schema 를 기반으로 추론한 타입을 사용할 수 있습니다.
다음 섹션에선 zod schema 에 대해 간단하게 소개하고, schema method parse, safeParse, preprocess, transform 을 설명하겠습니다.
소개할 메서드 이외에도 정말 많은 유용한 method 가 있으니, 관심 있는 분들은 링크 를 방문해보세요.
Zod Schema
zod 에서 Schema 는 단순한 string 타입부터 매우 복잡한 nested object 까지 모든 데이터 타입에 통용됩니다.
z 를 import 하면 다양한 타입을 위한 method 를 확인할 수 있습니다.
대부분 직관적인 네이밍을 가지고 있어 단순한 데이터 타입은 생략하고, 몇 가지 참고할 만한 메서드를 가볍게 소개하고 넘어갈까 합니다.
.optional
body: z.string().optional(),
다음과 같이 사용하면 body?: string 의 의미를 갖습니다.
.nullable
body: z.string().nullable(),
다음과 같이 사용하면 body: string | null 의 의미를 갖습니다.
이 경우, body 필드가 parse 대상에 없는 경우 Error 를 던집니다.
.nullish
body: z.string().nullish(),
다음과 같이 사용하면 body?: string | null | undefined 의 의미를 갖습니다.
위 예시는 z.string().optional().nullabe() 과 동일합니다.
z.enum
const Fish = z.enum(['Salmon', 'Tuna', 'Trout']);
console.log(Fish.enum); // => {Salmon: "Salmon", Tuna: "Tuna", Trout: "Trout"};
console.log(Fish.enum.Salmon); // => "Salmon"
console.log(Fish.options); // => ["Salmon", "Tuna", "Trout"]
Zod 는 enum 을 위한 자체적인 메서드를 지원합니다.
enum 으로 생성한 값은 .enum, .options 으로 다양한 값으로 사용할 수 있습니다.
z.nativeEnum
enum FishEnum {
Salmon = 'Salmon',
Tuna = 'Tuna',
Trout = 'Trout',
}
const Fish = z.nativeEnum(FishEnum);
앞서 소개한 z.enum() 이 enum 을 정의하거나 유효성을 검증하는 가장 추천되어지는 방식이지만, 이미 존재하는 enum 을 사용해야 하는 경우도 있습니다.
이럴 경우, z.nativeEnum 을 사용하여 스키마를 정의할 수 있습니다.
z.discriminatedUnion
const thing = z
.discriminatedUnion('type', [
z.object({ type: z.literal('human'), name: z.string() }),
z.object({ type: z.literal('fish'), species: z.array(z.string()) }),
])
.parse({ type: 'human', name: '박종호' });
if (thing.type === 'human') {
console.log(thing.name); // thing: { type: "human"; name: string; }
} else {
console.log(thing.species); // thing: { type: "fish"; species: string[]; }
}
zod 는 Discriminated Union 을 위한 메서드도 제공합니다.
첫 번째 인자로 타입을 좁힐 수 있는 대상을 지정하고, 다음 인자로 ZodSchema[] 를 넣어주면 parse 된 대상은 좁혀진 타입으로 추론됩니다.
z.infer
const Post = z.object({
userId: z.number(),
id: z.number(),
title: z.string(),
body: z.string(),
});
type Post = z.infer<typeof Post>;
// type Post = {
// id: number;
// userId: number;
// title: string;
// body: string;
// }
infer 를 사용하면 만들어 둔 스키마를 기반으로 타입 추론을 해줍니다.
Zod Method
앞서 언급했다시피, 아주 유용한 메서드인 parse, safeParse, preprocess, transform 에 대해 간략히 설명하겠습니다.
.parse
앞서 계속해서 나왔던 parse 메서드입니다.
ZodSchema.parse() 의 형태로 사용하며, 만든 Schema 가 인자에 들어오는 대상을 parse 할 수 있는지 검증하고,
유효하다면, 반환되는 값이 schema 타입으로 추론되도록 합니다.
유효하지 않다면 error 를 throw 합니다.
const name: unknown = '박종호';
const 박종호 = z.string().parse(name); // Type => 박종호: string
비단 앞에서 예시로 든 API 반환값을 parsing 하는 용도 외에도 다양한 방식으로 사용할 수 있습니다!
가령, payload 에 들어갈 값 중에 id 를 걸러줘야 하고, 해당 값을 넣으면 서버에서 오류를 뱉는다고 가정해봅시다. 그렇다면 다음과 같은 방식을 사용할 수 있을 겁니다.
function fetchSomething(payload: { id: string; name: string; content: string }) {
const newPayload = Object.fromEntries(Object.entries(payload).filter(([key, value]) => key !== 'id'));
// do something...
}
그러나, payload 에 또 다른 값이 영향을 주어서 filter 해야 하는 값이 또 추가된다면 해당 로직을 재수정 해야하고, 이는 매우 귀찮은 작업입니다.
이를 parse 로 해결할 수 있습니다.
type Something = z.infer<typeof Something>;
const Something = z.object({
name: z.string();
content: z.string();
})
function fetchSomething(payload: Something) {
const newPayload = Something.parse(payload);
// do something...
}
로직이 매우 간단해지고, 다른 필드가 추가적으로 들어오더라도 안전하게 payload 를 서버에 넘겨줄 수 있습니다.
.safeParse
앞서 소개한 parse 는 인자가 parsing 을 통과하지 못하면 Error 를 throw 합니다.
그러나, error 가 throw 되는 것을 원치 않는 경우도 있을 겁니다.
예를 들어, parsing 에 실패했을 때 다른 로직을 실행할 수도, 기존 값을 수정할 수도 있을 것입니다.
이러한 상황에서 safeParse 는 아주 적합한 메서드이며, 다음과 같은 타입을 가집니다.
.safeParse(data:unknown):
{ success: true; data: T; }
| { success: false; error: ZodError; }
let name: unknown = '박종호';
console.log(z.string().safeParse(name)); // => { success: true; data: "박종호" }
name = 1;
console.log(z.string().safeParse(name)); // => { success: false; error: ZodError }
const { success, data, error } = z.string().safeParse(name);
if (!success) {
// do something!!
}
.preprocess
때때로 Schema 에 통과하기 전 값을 변형시키고 싶은 경우가 있습니다.
예를 들어, 서버에서 넘겨주는 데이터 인터페이스가 바뀌었고
하위 호환성을 위해 기존 인터페이스를 유지 시켜줘야 할 필요가 있는 경우 preprocess 를 유용하게 사용할 수 있습니다.
const PostV2 = z.preprocess(
(input: any) => {
input.subtitle = input.version === 1 ? '' : input.subtitle;
// or input.subtitle ??= ""
return input;
},
z.object({
userId: z.number(),
id: z.number(),
title: z.string(),
body: z.string(),
subtitle: z.string(),
}),
);
.transform
transform 은 Schema 를 통과한 데이터를 변형시켜 줄 때 사용합니다.
서버에서 넘겨준 데이터와 클라이언트에서 렌더링을 위해 필요한 데이터의 인터페이스가 다른 경우가 흔히 있습니다.
이런 경우, 값을 가공하는 역할을 Schema Validation Layer 에 위임함으로써 주 로직을 보다 깔끔하게 관리할 수 있습니다.
export type Url = z.infer<typeof Url>; // Type Inference => Url: string
export const Url = z
.object({
protocol: z.string(),
host: z.string(),
pathname: z.string(),
})
.transform(({ protocol, host, pathname }) => {
return `${protocol}//${host}${pathname}`;
});
정리
- Schema Validation Layer 를 추가하면 주 로직을 깔끔하게 관리할 수 있습니다.
- Zod 에서 제공하는 메서드를 사용하면 Schema Validaition 을 손쉽게 할 수 있습니다.
- FYI) superstruct 는 zod 에 비해 비교적 적은 번들 사이즈를 가집니다. 제공하는 기능도 비슷하니 참고해보시는 것도 좋습니다.